

주변 지인이 환율 정보를 매일 알아서 업데이트해주는 방법이 없냐고 해서 최근 나를 편하게 서포트해주고 있는 스프레드 시트를 이용해서 만들어주었다. 물론 엑셀도 가능하지만 오류도 많은 편이고 조금 귀찮다..(필자: ISTP) 아무튼 그런데! 스프레드 시트를 이용하면 아주 간편하게 매일 자동으로 업데이트해주는 환율 데이터를 만들 수 있는 방법이 있어 작성해보겠다.
크롤링 정보
- 활용 정보: 네이버 시장지표 미국 USD/KRW (달러/원화)
- 크롤링 페이지 URL: https://finance.naver.com/marketindex/exchangeDetail.naver?marketindexCd=FX_USDKRW
https://finance.naver.com/marketindex/exchangeDetail.naver?marketindexCd=FX_USDKRW
1,384.60 원 전일대비 0.60 (+ 0.04% ) 2024.07.10 15:38 하나은행 고시회차 301회 1개월 3개월 1년 3년 5년 10년 환율계산기 (매매기준율 기준) 미국 달러 기준 대한민국 원 기준 관련 뉴스 원/달러 환율, 파월
finance.naver.com
크롤링 과정 기초
1. 개발자 도구 진입

네이버 USD/KRW 환율 정보 페이지에서 스크롤을 쭉 내려 '일별 시세' 화면을 포커스해주자.
그리고 <Ctrl + Shift+ i> 단축키를 동시 입력하면 오른쪽에 개발자 도구 영역이 나타난다.
2. 개별 페이지 진입
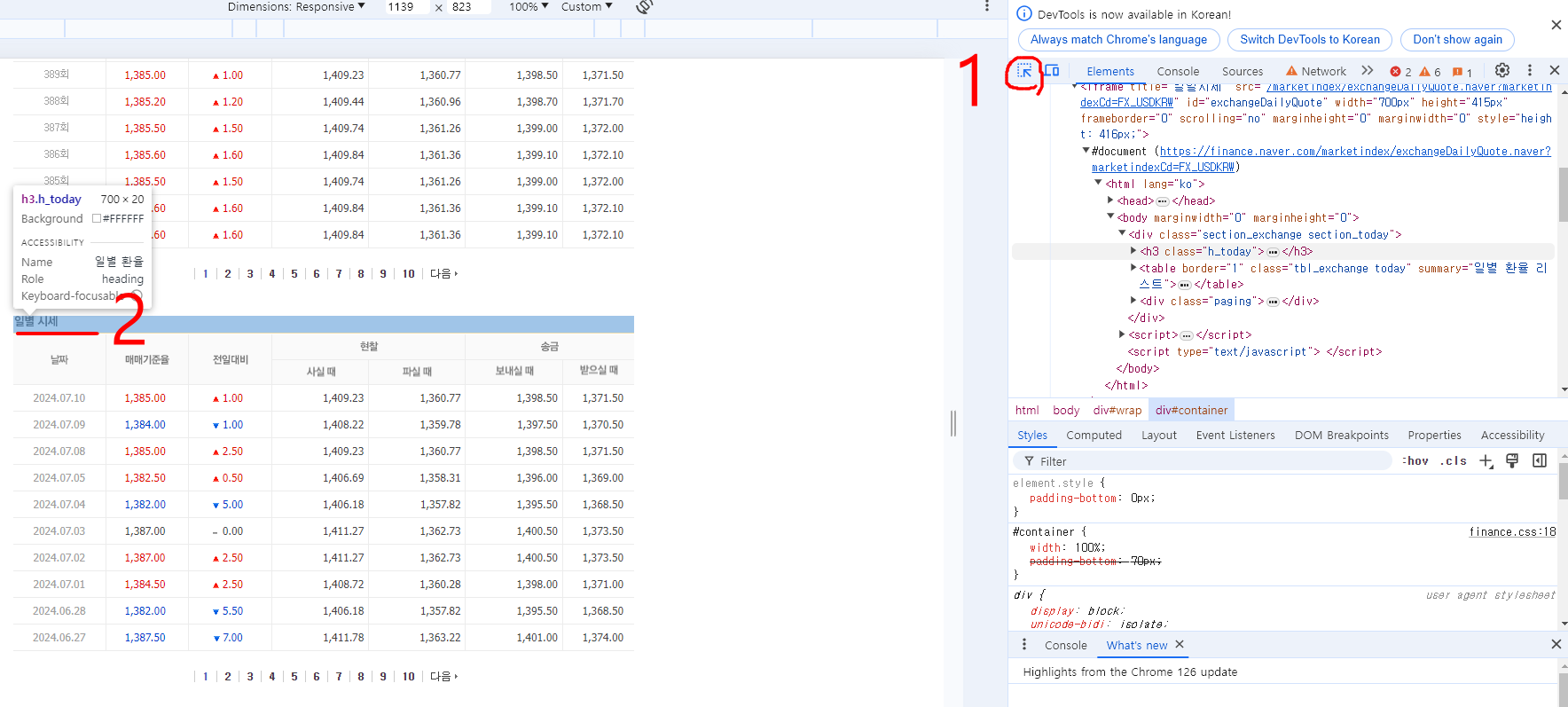

1 번에서 화살표(select~~)를 한번 클릭하면 화살표가 파란색으로 변경되는데 이 상태로 2번의 일별 시세 부분을 클릭하면 해당 부분의 코드가 보인다.
그리고 개발자 도구 영역에서 스크롤을 조금만 올리면 #document로 시작하고 가로 안에 url이 써져 있는 부분이 있는데, 여기에 커서를 올리고 오른쪽 마우스를 클릭하고 Open in new tab을 클릭해준다.
(※ 참고로 모든 URL이 이렇게 #document를 찾진 않는다. 개별 페이지로 진입하지 않고 해당 화면에서 바로 크롤링하는 경우가 오히려 더 많다.)
3. 크롤링 페이지 세팅


그러면 이렇게 일별 시세표만 나오는 페이지에 진입하게 되고 해당 페이지의 URL이
https://finance.naver.com/marketindex/exchangeDetail.naver?marketindexCd=FX_USDKRW 에서
https://finance.naver.com/marketindex/exchangeDailyQuote.naver?marketindexCd=FX_USDKRW
로 변경되는데, 여기서 페이지 번호 2번을 누르고 다시 1번을 누르면
https://finance.naver.com/marketindex/exchangeDailyQuote.naver?marketindexCd=FX_USDKRW&page=1
URL에 '&page=1'가 추가되는데, 해당 페이지 화면에 변경 사항은 없다.
추가 된 '&page=1' 는 페이지 번호 1번을 의미하며 '&page=2'는 페이지 번호 2번을 의미한다.
(※ 크롤링할 때 2번 페이지 번호 이상을 추출하고 싶다면 이 방법 응용해야 한다.)
4. 원하는 데이터의 XPATH 복사하기

개발자 도구를 열고 1.화살표를 클릭(파란색 상태)해주고 내가 가져오고 싶은 데이터를 2.클릭하면 3.해당 내용의 소스코드 내용이 나오는데 이 부분에 오른쪽 마우스를 눌러주고 Copy XPATH를 누르면 해당 영역의 XPATH를 복사한 것이다.
(일단 연습이니 매매기준율의 첫 번째 데이터만 가져와보자!)
5. IMPORTXML함수를 이용해 크롤링 결과 보기

IMPORTXML 수식어를 통해 이렇게 간편하게 크롤링해서 결과를 볼 수 있는데, 함수식은 다음과 같다.
=IMPORTXML("해당 페이지 URL", "해당 페이지에서 원하는 영역의 XPATH")
(※ 결과값이 같지 않은 이유는 오늘 기준의 데이터는 실시간으로 변동하여 적재되고 있기 때문이다. 오늘 이전의 데이터는 결과값이 동일)
IMPORTXML 오류가 난다면? 작은 따옴표(')가 아닌 큰 따옴표(")를 사용했는지, 문제가 없다면 XPATH를 다시 살펴보자!
6. 응용하기
방금은 하루치의 매매기준율 데이터를 가져왔다. 하지만 행의 모든 값을 가져오고 싶다면 어떻게 해야 할까?
보통은 tr[1] 부분이 행으로 이루어져있는데, /td[2] 부분을 지워주면 행 값이 되는 경우가 많다.
하지만 직접 확인해보는 것은 필수다.

역시나 <tr부분을 선택하니 해당 영역의 행이 잡힌다. 이 부분의 XPATH를 복사해주고 구글 스프레드 시트에서 적용하면,

이렇게 행에 있는 결과가 모두 나온다.
여러 날짜의 데이터를 가져오고 싶다면,

이렇게 XPATH의 tr[] 부분의 숫자를 1씩 늘려 여러 날짜의 데이터도 가져올 수 있다.
(※ 하지만 이건 해당 페이지에서 크롤링할 때만 해당하는 기준이고 페이지가 다를 경우에는 해당 페이지의 반복 요소를 본인이 알아서 찾아야 한다.)
이제 해당 데이터들은 매일매일 오늘의 기준에 맞춰서 데이터가 적재될 것이다!

크롤링 과정 심화
위 데이터에서 페이지 2번 이상의 데이터를 가져오고 싶다면,
https://finance.naver.com/marketindex/exchangeDailyQuote.naver?marketindexCd=FX_USDKRW&page=1 에서
&page=2로 변경하고 XPATH에 /html/body/div/table/tbody/tr[1] 적용하면 다시 2페이지의 1번 데이터를 가져온다.
응용해서 만들면 된다.
하지만 많은 양을 만들어야 한다면 조금 복잡해지기 때문에 직접 만들어놓은 자료를 공유하겠다!
PageNo, URL, X_PATH_PRE, X_PATH의 코드를 잘 살펴보자
[자료 공유] USD(달러), JPY(엔화), 기초 별 환율 데이터 3개
https://docs.google.com/spreadsheets/d/1b28d_2WB3ZyEXYKxhcAjkZlCjVyHUrYgG_6ZWATLrQE/edit?usp=sharing
ExchangeRate_Crawling
USD USD,전일대비,날짜,매매기준율,살 때,팔 때,보낼 때,받을 때,PageNO,URL,XPATH_PRE,XPATH TODAY(실시간 변동),↑5.3,2024.07.12,1,378.8,5.3,1,402.9,1,354.7,1,392.3,1,365.3,1,<a href="https://finance.naver.com/marketindex/exchangeDail
docs.google.com
[데이터 정제 내용 설명]
Page_No: 10행마다 숫자 1씩 늘어나는 함수(ex. 1~10행=1, 11~20행=2 ..)
URL: CONCAT함수를 이용해 Page_No를 URL 마지막에 붙혀 정제한 URL
XPATH_PRE: 1부터 10행까지 드래그 지정하고 <ctrl> + 드래그해서 1~10 을 반복하는 XPATH 생성
XPATH: XPATH_PRE 마지막에 " ] " 를 붙혀 정제를 마무리한 XPATH
화살표: 매매기준율 이전 날짜보다 높으면 "↑", 낮으면 "↓" 나오게끔 설정
유용하지만, IMPORTXML 기술의 특성상 양이 너무 많고 특정 경우에는 속도가 매우 느리기 때문에 많이는 힘들다.
응용하면 환율 뿐만 아니라 다른 페이지에서도 사용할 수 있다. 크롤링은 민감한 문제도 많기 때문에 잘 확인하고 하자!